Playing with NWS
1. How's the Weather?
Let's do some theorycrafting in Python Rust for a bit.1
I think weather forecasting data may be a good avenue of experimentation, so we'll make a program that fetches forecasts from the US National Weather Service (NWS) API for us. The API provides an interface which we will mangle in order to get exactly the data we want.
1.1. Why?
- Involves many different data types (datetimes, degrees, geocoords, strings, oh my!)
- Is measured frequently and made available as public data
- Is spacially and temporally dependent
- Provides a multitude of opportunities for analysis
- zeus.jpg
{kind=link}
1.2. A Word of Caution

The code below works, but is not pretty nor correct. Do not use this as a reference on how to write good code, but rather how to write code creatively, and with a degree of introspection.
We will discuss some of the hacks and design decisions as they come up, but not all. If you are not familiar with concurrent programming, HTTP, or Rust feel free to skip to the TL;DR section. :)
2. The API
The NWS API is a free service providing access to near-realtime weather data across the US. The API is located at api.weather.gov and the endpoints we're interested in are:
/points/{latitude},{longitude}
Returns metadata associated with a specific location, including the office and gridpoints required to retrieve forecast data.
/gridpoints/{office}/{grid X},{grid Y}/forecast/hourly
Returns a textual hourly forecast in a 2.5km grid area for the next week.
So it's worth mentioning that this API is a bit more complicated than it seems. There is a set of endpoints including /points/{x,y} that do not retrieve any weather data. They just provide contextual information, like a 'home page', showing you where you likely want to go next.
The other set includes those that retrieve weather data from the various offices around the country. The data is completely distributed in this fashion, and not accessible as a single resource or a public cache.
Each office is responsible for a specific section of the Grid that covers the US, and every single time you want to get some weather data for a location, you need to talk to the office that is responsible for that 2.5km block of the Grid.
On the surface, this is not an efficient system, but it gets worse. The distributed offices that serve our data are extremely inconsistent and often unstable. I did quite a bit of testing, iterating over random samples of 10 or so US cities at a time, and found that the metadata requests would never fail, but the subsequent request to the local 'office' data provider would fail about 25% of the time with a 500 HTTP Code.
A more rational agent may decide that due to these irregularities, we should consider a different API to abuse, but I WILL NOT ADMIT DEFEAT. 8)
3. The Code
The Code, which can be found at hg.rwest.io/nws_experiment is split into two separate crates:
weatherthe library source code, which contains Type definitions and API functionsbinthe program sources, containing executable code
You can run an API test with make demo, which compiles the
workspace and runs the get program with default values
supplied. The other programs (parse_cities, get_rand, write)
can be executed in any order, without arguments, using the data
files in data.
3.1. Library
3.1.1. lib.rs
The library is very simple. It includes one file for the API calls
(weather::api), and a lib.rs file with struct definitions at
the root of the crate (weather::City, weather::Point,
etc). There are also a couple of re-exports: anyhow::Result,
which is our lazy Result wrapper, and chrono::{DateTime, Utc}
for working with datetimes outside of the library.
All structs implement Debug (for debugging purposes) as well as
Deserialize and Serialize from the serde crate. These serde
traits allow us to take a Rust type and turn it into Data of
different types, such as JSON, RON, and Bincode, which we'll be do
quite frequently.
use serde::{Deserialize, Serialize}; use serde_json::Value; pub mod api; pub use anyhow::Result; pub use chrono::{DateTime, Utc}; // ... /// Result of Forecast query #[derive(Debug, Serialize, Deserialize)] pub struct Forecast { pub properties: ForecastProps, } // Inner properties object of Forecast #[derive(Debug, Serialize, Deserialize)] pub struct ForecastProps { pub updated: DateTime<Utc>, pub units: String, #[serde(rename(deserialize = "generatedAt"))] pub generated_at: DateTime<Utc>, pub elevation: Value, pub periods: Vec<ForecastPeriod>, } // ...
Some of the structs (City, Point and WeatherBundle) have
methods in addition to the serde traits. These are just little
type constructors:
// ... #[derive(Deserialize, Serialize, Debug)] pub struct City { pub city: String, pub state_id: String, pub lat: f32, pub lng: f32, } impl City { pub fn into_point(&self) -> Result<Point> { Ok(Point { lat: self.lat, lng: self.lng, }) } } #[derive(Debug, Serialize, Deserialize)] pub struct Point { pub lat: f32, pub lng: f32, } impl Point { // create a new 'Point' from (f32, f32) pub fn new(lat: &f32, lng: &f32) -> Result<Self> { Ok(Point { lat: *lat, lng: *lng, }) } } // ... /// Weather output representation #[derive(Debug, Serialize, Deserialize)] pub struct WeatherBundle { pub location: City, pub forecast: Vec<ForecastBundle>, pub updated: DateTime<Utc>, } impl WeatherBundle { pub fn new(loc: City, fcb: Forecast) -> Self { let mut vec = Vec::new(); for i in fcb.properties.periods.iter() { let i = ForecastBundle { start: i.start_time, end: i.end_time, temperature: i.temperature, wind_speed: i.wind_speed.to_string(), wind_direction: i.wind_direction.to_string(), short_forecast: i.short_forecast.to_string(), }; vec.push(i); } WeatherBundle { location: loc, forecast: vec, updated: fcb.properties.updated, } } }
3.1.2. api.rs
Setting aside our gripes with the NWS API, the fundamental network requests are relatively simple, and we can define them as simple functions. This isn't scalable, but doesn't need to be either (so w/e).
We use reqwest to get JSON data from the API. It's simple, asynchronous, and based on the tokio runtime which will come into play later.
[dependencies]
tokio = { version = "1", features = ["full"] }
reqwest = { version = "0.11.3", features = ["json"] }
# ...
The get_point, get_forecast, and get_forecast_hourly
functions call the API, and deserializes the response into
custom structs.
use crate::{Forecast, Point, PointInfo, Result}; pub use reqwest::{Client, StatusCode}; use std::env; /// User-Agent HTTP Header value pub static APP_USER_AGENT: &str = concat!(env!("CARGO_PKG_NAME"), "/", env!("CARGO_PKG_VERSION"),); pub async fn get_point(pnt: &Point, client: &Client) -> Result<PointInfo> { let mut url: String = String::from("http://api.weather.gov/"); for i in &["points/", &pnt.lat.to_string(), ",", &pnt.lng.to_string()] { url.push_str(i); } let response = client.get(&url).send().await?; let body = response.text().await?; let res: PointInfo = serde_json::from_str(&body)?; Ok(res) } pub async fn get_forecast(pnt: &PointInfo, client: &Client) -> Result<Forecast> { let response = client.get(&pnt.properties.forecast).send().await?; let body = response.text().await?; let res: Forecast = serde_json::from_str(&body)?; Ok(res) } pub async fn get_forecast_hourly(pnt: &PointInfo, client: &Client) -> Result<Forecast> { let response = client.get(&pnt.properties.forecast_hourly).send().await?; let body = response.text().await?; let res: Forecast = serde_json::from_str(&body)?; Ok(res) }
3.2. Binaries
3.2.1. get.rs
The get program is the simplest of the bunch. It takes two arguments (latitude, longitude) and prints the forecast for that location.
use std::env; use weather::api::{get_forecast, get_point, Client, APP_USER_AGENT}; use weather::{Point, Result}; #[tokio::main] async fn main() -> Result<()> { let args: Vec<String> = env::args().collect(); let lat: &f32 = &args[1].parse::<f32>()?; let lng: &f32 = &args[2].parse::<f32>()?; let pnt = Point::new(lat, lng)?; let client = Client::builder().user_agent(APP_USER_AGENT).build()?; let res = get_point(&pnt, &client).await?; let resf = get_forecast(&res, &client).await?; for i in resf.properties.periods.iter() { println!("{:#?}, {:#?}", &i.name, &i.detailed_forecast); } Ok(()) }
After compiling, the program can be executed with:
# weather {LAT} {LONG} # cd ./target/debug/ ./weather 40.7580 -73.9855
which will query the appropriate endpoints for a set of coordinates and print some data:
PointStatus: 200 OK ForecastStatus: 200 OK "This Afternoon", "Partly sunny. High near 76, with temperatures falling to around 74 in the afternoon. Southwest wind around 8 mph." "Tonight", "Partly cloudy. Low around 55, with temperatures rising to around 57 overnight. West wind 2 to 6 mph." "Saturday", "A slight chance of rain showers between noon and 3pm, then a slight chance of showers and thunderstorms. Mostly sunny. High near 76, with temperatures falling to around 74 in the afternoon. Northeast wind 2 to 9 mph. Chance of precipitation is 20%." [...]
This helps us confirm the API is working and is returning the data we expect. Our other programs don't rely on user input, which can make them difficult to debug. This little guy came in handy quite a lot, and was easy to change quickly to test the other API calls.
3.2.2. parse_cities.rs
I wasn't satisfied with just a static list of hand-picked coordinates, so I decided to get a list of all US cities and create random samples to test our programs with.
use std::fs::File; use std::io::Write; use weather::City; fn main() -> Result<(), csv::Error> { let mut input = csv::Reader::from_path("data/uscities.csv")?; let mut output = File::create("data/uscities.ron")?; for city in input.deserialize() { let city: City = city?; write!(&mut output, "{}\n", ron::ser::to_string(&city).unwrap())?; } Ok(()) }
The code is pretty straight-forward. We take all rows from our
input CSV file, and write them to a new RON file. We implicitly
skip some columns and only take the fields defined in City:
city, state_id, lat, lng.
One important thing to note is that we are writing a new line for each City. The right way to do this is by creating a parent object (such as an Array, which is allowed in RON). Ultimately I stuck with the newline approach, which I'm sure is extremely inefficient, but has some interesting implications for where and when data serialization occurs. I'll dig up that rabbit hole at a later date, but just to be clear, this probably isn't a good idea.
3.2.3. get_rand.rs
Here's where things start to get interesting. At this point we
have about 24k lines, with a city on each line, in a file:
data/uscities.ron.
As mentioned before I want to get random samples of cities for
testing. This is done quite subtly in the collect_lines
function:
for line in lines.into_iter() .choose_multiple(&mut rand::thread_rng(), 16) {...}
The choose_multiple function is from the
rand::seq::IteratorRandom trait, and allows us to specify the
number of items we want to collect. I found 16 to be the maximum
that this program allows, because it also dictates the number of
threads that the program spawns. This, of course is a horrible
idea, but I found it humorous knowing that such an unassuming
parameter can have such insane consequences :). It was fun bumping
the number into the hundos and seeing how dramatically the program
panics, but a real implementation would make use of a thread pool
and worker threads.
Don't worry about that other function read_lines. It's just used
in the aforementioned collect_lines function, which brings us to
the big ugly async fn main.
We collect those 16 lines, and create a new Vec to store
handles. Up to this point it's not that bad, but then comes the
giant for loop, where we iterate over the 16 random cities, and
create an async job or handle with tokio::spawn for each
one. Once we have our handles we just execute and .await each
one. The result is a forecast.ron file with anywhere from 0-16
sets of forecasts formatted as RON, with 1 WeatherBundle per
line. yay!
use rand::seq::IteratorRandom; use ron::de::from_str; use std::io::{self, BufRead}; use std::{fs::File, path::Path}; use tokio::fs::File as TFile; use tokio::io::{AsyncWriteExt, BufWriter}; use weather::{api, City, Point, Result, WeatherBundle}; /// Collect (lat,lng) values from file, return a Vec<Point> fn collect_lines(input_path: &str) -> Result<Vec<City>> { let mut result = Vec::new(); if let Ok(lines) = read_lines(&input_path) { for line in lines .into_iter() .choose_multiple(&mut rand::thread_rng(), 16) { if let Ok(city) = line { let pcity: City = from_str(&city)?; result.push(pcity); } } } Ok(result) } /// Returns an Iterator to the Reader of the lines of the file. fn read_lines<P>(path: P) -> io::Result<io::Lines<io::BufReader<File>>> where P: AsRef<Path>, { let file = File::open(path)?; Ok(io::BufReader::new(file).lines()) } #[tokio::main] async fn main() -> Result<()> { // Create a single reqwest::Client that is re-used let client = api::Client::builder() .user_agent(api::APP_USER_AGENT) .build()?; let input_path: &str = "data/uscities.ron"; // ../data/uscities.ron let cities: Vec<City> = collect_lines(&input_path)?; // get our list of cities let out_file = TFile::create("data/forecast.ron").await?; let mut handles = Vec::new(); // stores async tasks // loop over the sample, spawning two new async handles for the // network client and out_file writer. for city in cities { let pnt = Point::new(&city.lat, &city.lng)?; let out = out_file.try_clone().await?; let client = client.clone(); let mut writer = BufWriter::new(out); let handle = tokio::spawn(async move { let res = api::get_point(&pnt, &client).await.unwrap(); let result = api::get_forecast_hourly(&res, &client).await; if let Ok(r) = result { println!("{:#?} - got result", &city.city); let output = WeatherBundle::new(city, r); let ronr = ron::ser::to_string(&output) // ron::ser::PrettyConfig::new() .unwrap() .into_bytes(); writer.write_all(&ronr).await.unwrap(); writer.write_all(b"\n").await.unwrap(); writer.flush().await.unwrap(); } }); handles.push(handle) } for handle in &mut handles { handle.await?; } Ok(()) }
3.2.4. write.rs
Once we have a set of forecasts in forecast.ron we're ready to
insert some data into our database! This one was much more quick
and dirty. Everything is stuffed in the main function (which has
no Result return type), and runs in a single thread. It's a mess
so here are the highlights:
- reads a file
data/forecast.ron - deserializes each line as a RON WeatherBundle and push to a Vec called
result - setup and start a RocksDB instance at
data/dbwith two column families:locationandforecast. - for each WeatherBundle:
- first add a key/val pair to the
forecastcf for each ForecastBundle it contains, using Bincode to serialize keys and vals. - then add a single key/val pair to the
locationcf, again using Bincode. - Query the
locationcf using thelocationkey we just inserted, print the result without using Bincode (uses unsafe code to manually align bytes to f32).
- first add a key/val pair to the
- compact both cf's, writing the contents from the MemTable2 to SST
files on disk in
data/db.
One big glaring issue is that we are using the same key for every ForecastBundle in a WeatherBundle. What this is actually doing is replacing the value for the same key over and over. This is useful to me for understanding how RocksDB works with values that get changed frequently, but it is easy to make this work "correctly" by enumerating the ForecastBundles, and using their index to create unique keys:
for (idx,c) in fc.into_iter().enumerate() { let key = bincode::serialize([&i.location.city, &idx]).unwrap(); // city0, city1, city2 // ...
Another is that each step in this program works sequentially. We have two separate handles for each column family, but we don't leverage this fact to use them both concurrently, we just use them one at a time. RocksDB has some really cool interfaces for working with multiple column families, caches, and even databases concurrently, but these are out of scope for the time being.
use rocksdb::{ColumnFamilyDescriptor, Options, DB}; use ron::de::from_str; use std::fs::File; use std::io::{self, BufRead}; use weather::WeatherBundle; // from rust_rocksdb/tests // fn get_byte_slice<T: AsRef<[u8]>>(source: &'_ T) -> &'_ [u8] { // source.as_ref() // } fn main() { let input_path: &str = "data/forecast.ron"; let input = File::open(&input_path).expect("couldnt open file"); let mut result: Vec<WeatherBundle> = Vec::new(); let db_path: &str = "data/db"; { for line in io::BufReader::new(input).lines() { // this is bloat! match from_str(&line.unwrap()) { Ok(x) => result.push(x), Err(e) => { println!("error: {}", e); std::process::exit(1); } } } } { let loc_opts = Options::default(); let fc_opts = Options::default(); let mut db_opts = Options::default(); db_opts.create_if_missing(true); db_opts.create_missing_column_families(true); let loc_cf = ColumnFamilyDescriptor::new("location", loc_opts); let fc_cf = ColumnFamilyDescriptor::new("forecast", fc_opts); let db = DB::open_cf_descriptors(&db_opts, db_path, vec![loc_cf, fc_cf]).unwrap(); let cf1 = db.cf_handle("location").unwrap(); let cf2 = db.cf_handle("forecast").unwrap(); for i in result.into_iter() { let fc = i.forecast; for c in fc.into_iter() { let key = bincode::serialize(&i.location.city).unwrap(); let val = bincode::serialize(&[ c.start.timestamp().to_string(), c.wind_speed, c.wind_direction, c.temperature.to_string(), c.short_forecast, ]) .unwrap(); db.put_cf(cf2, key, val).unwrap(); } let key = bincode::serialize(&i.location.city).unwrap(); let val = bincode::serialize(&[i.location.lat, i.location.lng]).unwrap(); db.put_cf(cf1, &key, val).unwrap(); println!("inserted: {}", i.location.city); if let Some(i) = db.get_cf(cf1, &key).unwrap() { let (_pre, res, _suf) = unsafe { i.align_to::<f32>() }; println!("coords: {:#?}", res); } } db.compact_range_cf(cf1, None::<&[u8]>, None::<&[u8]>); db.compact_range_cf(cf1, None::<&[u8]>, None::<&[u8]>); } }
3.3. Files
uscities.csv
"city","city_ascii","state_id","state_name","county_fips","county_name","lat","lng","population","density","source","military","incorporated","timezone","ranking","zips","id" "New York","New York","NY","New York","36061","New York","40.6943","-73.9249","18713220","10715","polygon","FALSE","TRUE","America/New_York","1","11229 11226 11225 11224 11222 11221 11220 11385 10169 10168 10167 10165 10162 10282 10280 10040 10044 11109 11104 11105 11379 11378 11377 11697 11694 11692 11693 11691 10271 10279 10278 10075 10302 10301 10452 11451 10475 10474 10471 10470 10473 10472 11228 11223 10103 11368 11369 11366 11367 11364 11365 11362 11363 11360 11361 10028 10029 10026 10027 10024 10025 10022 10023 10020 10021 11212 11213 11210 11211 11216 11217 11214 11215 11218 11219 10152 10153 10154 10307 10306 10305 11429 10310 10311 10312 10314 11432 11433 11430 11436 11434 11435 10453 10451 10457 10456 10455 10454 10459 10458 10128 10004 10005 10006 10007 10001 10002 10003 10009 11238 11239 11230 11231 11232 11233 11234 11235 11236 11237 11375 11374 11371 11370 11373 11372 10170 10171 10172 10173 10174 10177 11351 10039 10038 10035 10034 10037 10036 10031 10030 10033 10032 11201 11208 11203 11205 11204 11207 11206 11209 11411 11412 11413 11414 11415 11416 11417 11418 11419 11101 11102 11103 11106 11001 11005 11004 10065 10069 10199 10309 10308 10304 10303 11428 11421 11420 11423 11422 11425 11424 11427 11426 10466 10467 10464 10465 10462 10463 10460 10461 10468 10469 10119 10115 10112 10110 10111 11359 11358 11357 11356 11355 11354 10019 10018 10013 10012 10011 10010 10017 10016 10014 10008 10041 10043 10055 10060 10080 10081 10087 10090 10101 10102 10104 10105 10106 10107 10108 10109 10113 10114 10116 10117 10118 10120 10121 10122 10123 10124 10125 10126 10129 10130 10131 10132 10133 10138 10150 10151 10155 10156 10157 10158 10159 10160 10163 10164 10166 10175 10176 10178 10179 10185 10203 10211 10212 10213 10242 10249 10256 10258 10259 10260 10261 10265 10268 10269 10270 10272 10273 10274 10275 10276 10277 10281 10285 10286 10313 11120 11202 11241 11242 11243 11245 11247 11249 11251 11252 11256 11352 11380 11381 11386 11405 11431 11439 11499 11690 11695","1840034016" "Los Angeles","Los Angeles","CA","California","06037","Los Angeles","34.1139","-118.4068","12750807","3276","polygon","FALSE","TRUE","America/Los_Angeles","1","90291 90293 90292 91316 91311 90037 90031 90008 90004 90005 90006 90007 90001 90002 90003 90710 90089 91344 91345 91340 91342 91343 90035 90034 90036 90033 90032 90039 90247 90248 91436 91371 91605 91604 91607 91601 91602 90402 90068 90069 90062 90063 90061 90066 90067 90064 90065 91326 91324 91325 90013 90012 90011 90010 90017 90016 90015 90014 90019 90090 90095 90094 91042 91040 91411 91352 91356 90041 90042 90043 90044 90045 90046 90047 90048 90049 90018 91423 90210 91303 91304 91306 91307 90079 90071 90077 90059 91608 91606 91331 91330 91335 90026 90027 90024 90025 90023 90020 90021 90028 90029 90272 90732 90731 90230 91406 91405 91403 91402 91401 91367 91364 90038 90057 90058 90744 90501 90502 90009 90030 90050 90051 90053 90054 90055 90060 90070 90072 90074 90075 90076 90078 90080 90081 90082 90083 90084 90086 90087 90088 90093 90099 90134 90189 90213 90294 90295 90296 90733 90734 90748 91041 91043 91305 91308 91309 91313 91327 91328 91329 91333 91334 91337 91346 91353 91357 91365 91392 91393 91394 91395 91396 91404 91407 91408 91409 91410 91412 91413 91416 91426 91470 91482 91495 91496 91499 91603 91609 91610 91611 91612 91614 91615 91616 91617 91618","1840020491" "Chicago","Chicago","IL","Illinois","17031","Cook","41.8373","-87.6862","8604203","4574","polygon","FALSE","TRUE","America/Chicago","1","60018 60649 60641 60640 60643 60642 60645 60644 60647 60646 60616 60617 60614 60615 60612 60613 60610 60611 60618 60619 60827 60638 60639 60634 60636 60637 60630 60631 60632 60633 60605 60604 60607 60606 60601 60603 60602 60609 60608 60106 60661 60660 60659 60652 60653 60651 60656 60657 60654 60655 60623 60622 60621 60620 60626 60625 60624 60629 60628 60707 60499 60664 60666 60668 60669 60670 60673 60674 60675 60677 60678 60680 60681 60682 60684 60685 60686 60687 60688 60689 60690 60694 60695 60696 60699","1840000494"
uscities.ron
(city:"New York",state_id:"NY",lat:40.6943,lng:-73.9249) (city:"Los Angeles",state_id:"CA",lat:34.1139,lng:-118.4068) (city:"Chicago",state_id:"IL",lat:41.8373,lng:-87.6862)
forecast.ron
(location:(city:"Government Camp",state_id:"OR",lat:45.3022,lng:-121.7528),forecast:[(start:"2021-05-26T08:00:00Z",end:"2021-05-26T09:00:00Z",temperature:40,wind_speed:"5 mph",wind_direction:"WNW",short_forecast:"Mostly Cloudy"),(start:"2021-05-26T09:00:00Z",end:"2021-05-26T10:00:00Z",temperature:39,wind_speed:"5 mph",wind_direction:"WNW",short_forecast:"Mostly Cloudy"), // ...

Figure 1: ron > json
4. MapReduce 101
A full MapReduce system performs the following operations:
- Map: each worker node applies the map function to the local data, and writes the output to a temporary storage. A master node ensures that only one copy of the redundant input data is processed.
- Shuffle: worker nodes redistribute data based on the output keys (produced by the map function), such that all data belonging to one key is located on the same worker node.
- Reduce: worker nodes now process each group of output data, per key, in parallel.
Logically speaking, a MapReduce program works by:
- first splitting data into a new list of values:
Map(data) → list(k1,v1)
Then we group all values by key:
list((k1,v1)) -> (k2, list(v2))
and perform the specified reduce function:
Reduce(k2, list(v2)) → list((k3, v3))
We call the magical Reduce function once (or multiple times) on each group of values, with each call returning one, multiple, or empty pairs. The return of all calls are collected to create our final output.
This infrastructure is great for bulk processing different types of data concurrently across shard nodes into a common domain, which is exactly what we're looking to do.
4.1. WordCount
The conventional example is a "wordcount" program, where data is a
text document – which is split into lines, grouped by word, and
summarized into an aggregate word count list.
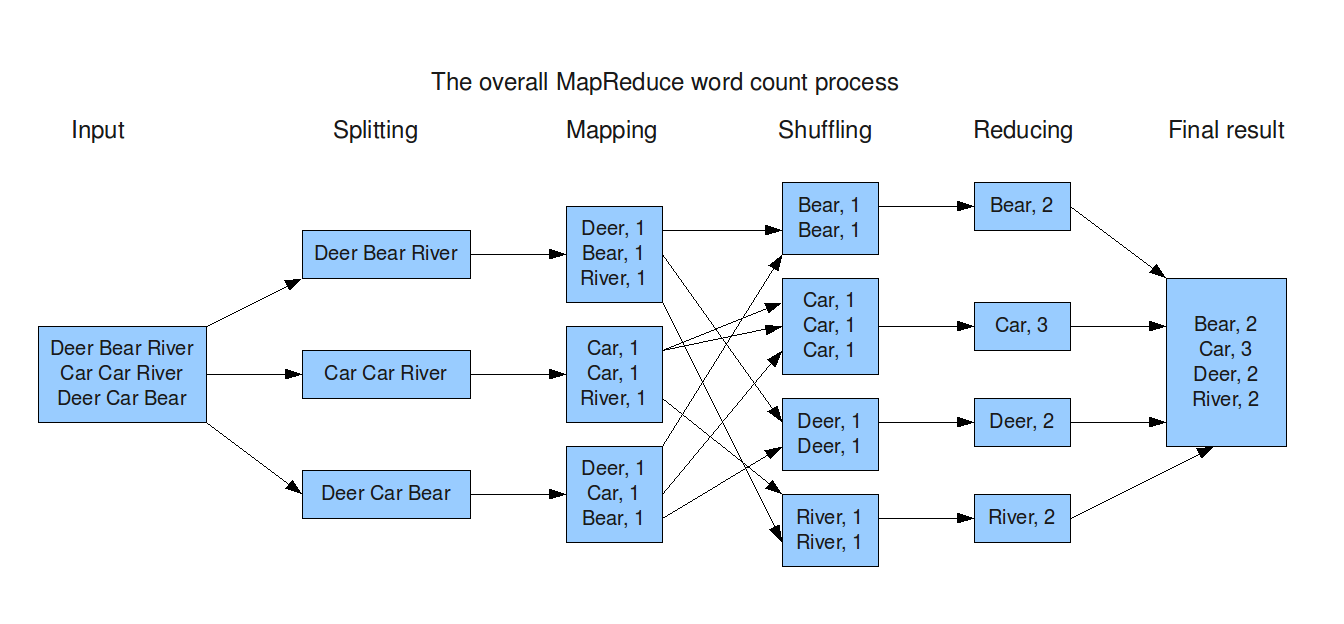
4.2. NumCount
A similar program is the map_reduce example in the Rust by Example book, which performs a mapreduce job on chunks of integers.
4.3. Thoughts on ETL
It's worth noting that the process we achieve is an ETL (Extract, Transform, Load) job. We are extracting data from somewhere, transforming that data, and loading it into a database. This is not MapReduce, but the MapReduce framework can be used to build ETL jobs, and provides an opinionated method of doing so.
The term ETL and its cousin ELT (Extract, Load, Transform) comes from the world of database engineers, but is a fitting paradigm for so many areas of programming. For example, in a CLI program, you may Extract command-line options, Transform those into a config, and Load that config to start your application.
We are exploring systems, and so are far more concerned with how a set of processes work together to distribute many different ETL jobs efficiently. Thinking through the lens of MapReduce helps us think of what we're doing with a higher degree of consideration for other parts of our system.
5. TL;DR
We can now insert a weather forecast from a web API for any city or coordinate pair in the US into an in-memory database. This is done by:
- making a series of web requests, parsing the response, and writing the parsed response to a file on disk,
- iterating over contents of the file and writing data into a database instance.
Step 1 is done concurrently across an unbound number of threads. Step 2 is performed synchronously.
Along the way, we learned about concurrent programming, data serialization, an unstable weather API, and most importantly, how to do it better next time.
If you want to play with it, pull the source then run make demo to
get the current forecast for Times Square printed to stdout.
The other program binaries can be run in debug-mode with cargo run
--bin $bin_name --features 'all' , or in release-mode from the
source root by executing ./target/release/$bin_name.
5.1. Is this MapReduce?
No. At most we are performing the first step only - Mapping data to a list of key,val pairs. Our program does some things concurrently, but it is missing something very important that prevents us from scaling in the current state: Inter-process communication (IPC).
Ultimately, IPC will be handled later, and over time our system will have growth spurts that cause it to bear a resemblance to MapReduce. Or maybe we think of a different way of doing things altogether. We'll see.

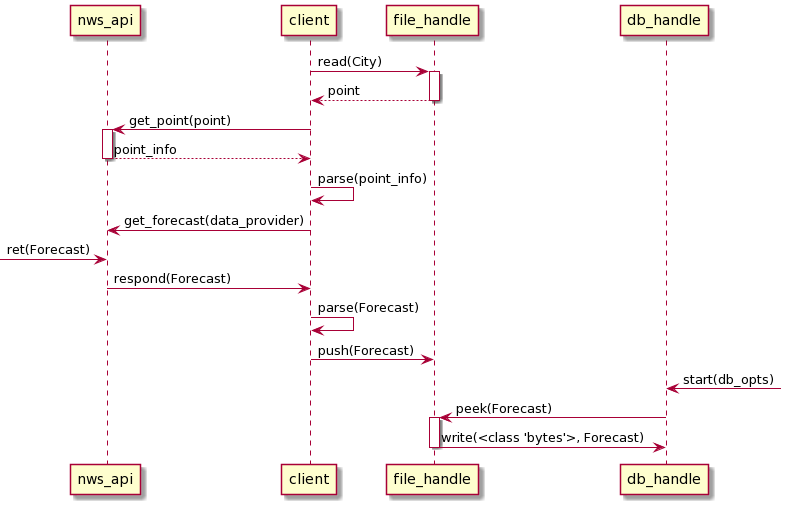
5.2. A Diagram